
When a client came to us running 1.5 petabytes of data on Amazon Redshift, the platform wasn’t broken — it was just expensive, inflexible, and increasingly painful to maintain. Three months later, that same data lived on a modern Snowflake + Apache Iceberg lakehouse at roughly 400 GB. A 73% reduction in storage. Zero data loss. No unplanned downtime.
Here’s exactly how we did it.

The Situation
The client had accumulated 1.5 PB of data in Redshift over several years. The largest single table had grown to 169 TB. The platform worked — queries ran, reports got produced — but three things were forcing a change:
Cost. At 1.5 PB, storage and compute costs were one of the largest line items in the engineering budget. A significant portion of that data was redundant, poorly compressed, or partitioned in ways that made queries scan far more than they needed to.
Vendor lock-in. Redshift’s proprietary format made it difficult to use the data anywhere else. As the team started exploring ML pipelines, real-time analytics, and multi-cloud options, being locked into a single ecosystem was becoming a strategic problem.
Operational overhead. Managing cluster sizing, distribution keys, and sort keys at this scale was consuming engineering time that should have gone toward analytics work.
They needed a modern lakehouse — but migrating 1.5 PB cleanly, including a 169 TB table, was not a straightforward lift.
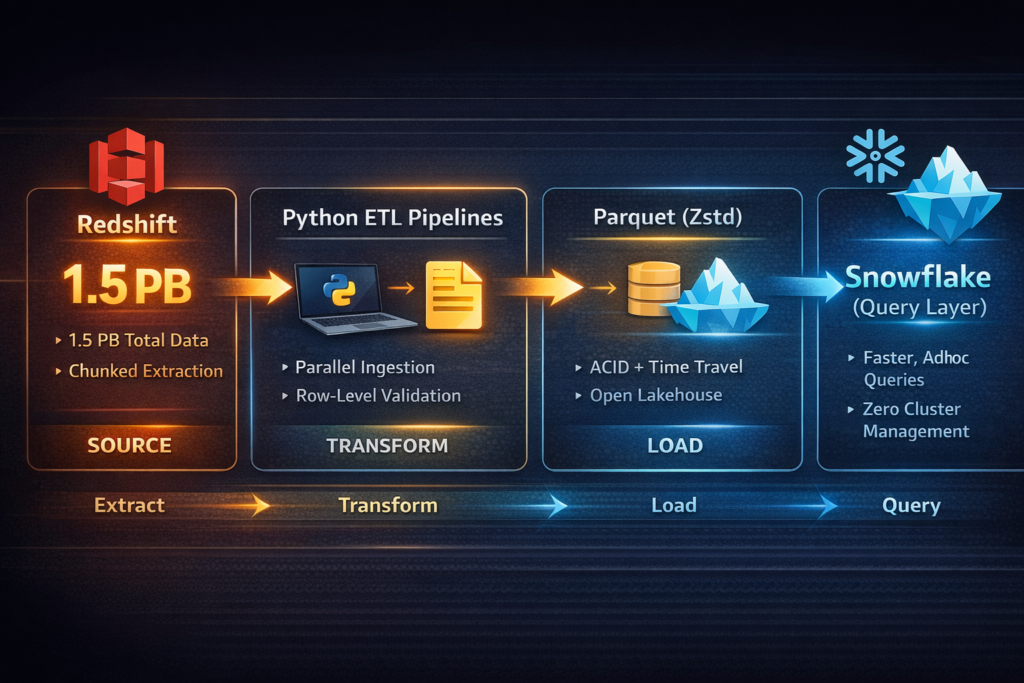
The Architecture We Chose
We designed the target stack around two decisions:
Snowflake as the primary compute and query layer — familiar SQL interface, strong performance on analytical workloads, and no cluster management overhead.
Apache Iceberg as the table format on S3 — open standard, ACID transactions, schema evolution, time travel, and no vendor lock-in. Any future tool (Spark, Trino, Athena, DuckDB) can read Iceberg tables directly. This was the insurance policy against ever being locked in again.
Data would move from Redshift → Parquet files (compressed with Zstd) → Iceberg tables on S3 → queryable via Snowflake.
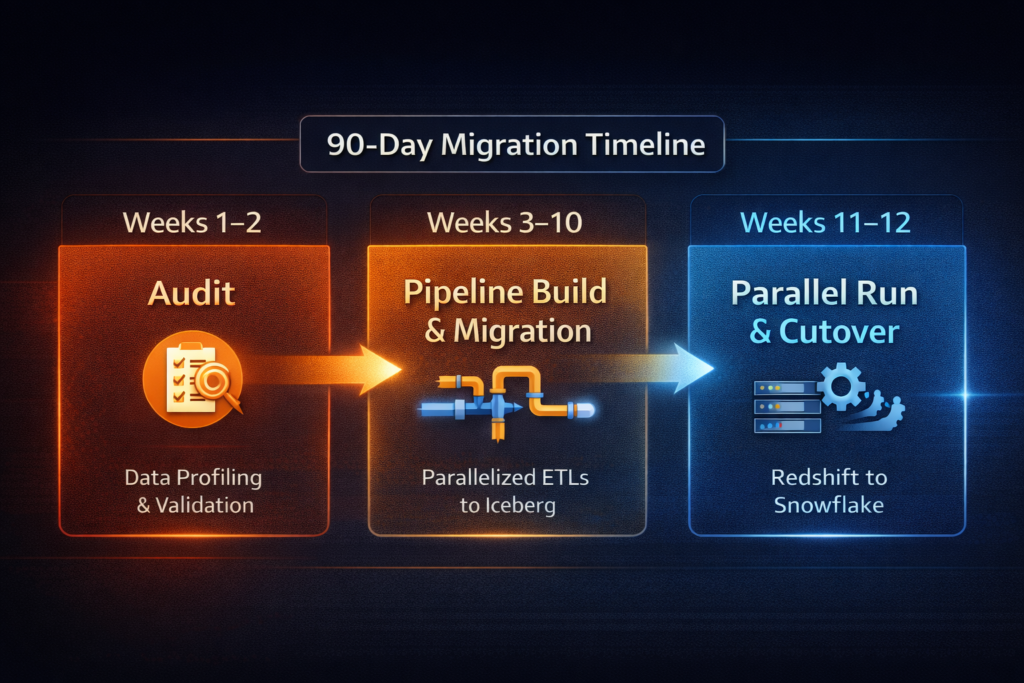
The Migration: Three Phases Over 90 Days
Phase 1 — Audit (Weeks 1–2)
Before moving anything, we profiled every table: row counts, data types, compression ratios, query patterns, and partition strategies. This step immediately revealed where the 1.5 PB was actually coming from — years of uncompressed data, suboptimal column types, and duplicated records that had never been cleaned up.
This audit shaped everything. We knew exactly what we were dealing with before writing a single line of migration code.
Phase 2 — Pipeline Build and Staged Migration (Weeks 3–10)
We built Python extraction pipelines to pull data from Redshift in chunks, transform it to optimized Parquet (proper types, Zstd compression, intelligent partitioning), and load it into Iceberg tables.
For most tables, this was automated at scale. The 169 TB table required a different approach — a parallelized, chunked ingestion process with row-level validation at each stage. Every chunk was reconciled: row counts checked, checksums verified, business logic spot-checked. Nothing was marked complete until it passed.
Phase 3 — Parallel Run and Cutover (Weeks 11–12)
We ran Redshift and Snowflake side by side for two weeks, running identical queries against both systems and comparing outputs. When the data team confirmed full parity, we executed the cutover during a planned maintenance window.
Redshift was decommissioned. No unplanned downtime. No data loss.

The Results
The 73% storage reduction — from 1.5 PB down to ~400 GB — came from three things working together: Zstd compression in Parquet, intelligent partitioning that eliminated redundant data scanning, and years of data type bloat finally cleaned up. The data didn’t shrink. The waste did.
Beyond storage:
• The 169 TB table migrated with full integrity — the highest-risk element of the project, delivered without incident
• Query performance improved on analytical workloads due to Iceberg’s partition pruning and Parquet’s columnar storage
• The platform is now fully open — Iceberg tables can be queried by any tool the team chooses in the future
• Engineering operational overhead dropped significantly — no more cluster tuning or Redshift-specific performance firefighting
• Storage costs dropped dramatically — 400 GB on object storage is a fraction of the cost of 1.5 PB on Redshift managed storage
What Made This Work
Two things: the upfront audit and the parallel run.
Most migration projects fail or go over time because teams underestimate what they’re actually migrating. The two-week audit before writing any code meant we had no surprises at week 8. We knew where every gigabyte was coming from.
The two-week parallel run before cutover meant the client’s team had confidence in the new platform before anyone pulled the switch. There was no leap of faith — just a clean handover.
Is Your Data Platform Due for a Modernization?
If you’re running on Redshift, a legacy warehouse, or a platform that’s become expensive and difficult to maintain — this is what a well-executed migration looks like. Phased, validated, no drama.
If you’re thinking about a similar move and want to talk through what it would look like for your data, reach out here or book a free 30-minute call.
Technologies used: Amazon Redshift · Snowflake · Apache Iceberg · Apache Parquet · Python · Amazon S3
Written by Nitin Jain — Founder, CDataInsights | Data Engineering & AI Strategy | Toronto
CDataInsights © Copyright 2026. Designed by CDataInsights.com

